Model Weights Distribution: The Terabyte Page Fault
Abstract — Moving 1TB of model weights into GPU memory; not once at deployment, but continuously as inference workloads scale and swap, is a dominant systems constraint in modern inference. A cold start is actually a distributed memory orchestration problem. This post examines how modern inference stacks are evolving into Distributed Virtual Memory Subsystems, moving tensors directly from storage fabrics to VRAM with zero CPU intervention.
These views are my own: a synthesis of public research, architectural reasoning, and observations from watching this space evolve.
Introduction: The Hidden Tax on Intelligence
In the mental model of AI serving, deployment is a simple arrow:
Model → GPU. In reality, that arrow represents a massive infrastructure tax.
We are moving hundreds of gigabytes of structured tensor state from cold storage to VRAM under intense time pressure. This happens during every autoscaling event, every expert swap in an agentic workflow, and every model eviction.
- Serverless inference scales to zero between requests; every scale-up is a cold start
- Autoscaling spins up dozens of replicas under load spikes; each replica must load the full model before serving a single token
- Agentic workflows dynamically route between expert models (code generation → vision → reasoning) where each swap requires loading or paging in a different model
- Multi-tenant clusters evict models from GPU memory under pressure; re serving a request means re-loading
- LoRA adapter injection layers per request customization onto base models at serving time
- A/B testing and canary deployments require multiple model versions to be loadable on demand
If your GPUs are idle for 60 seconds waiting on storage I/O, you aren't just losing users; you’re burning money at H100/B200 spot pricing. Training optimizes for throughput over hours. Inference optimizes for latency on every request. That is why weight distribution is no longer a storage problem, it’s a memory mobility problem.
The Three Regimes of Failure
The naive path using torch.load() to pull a model from a central registry fails at scale:
- The CPU Bottleneck: Default loaders are opaque. The CPU becomes the bottleneck, deserializing data at < 1 GB/s while the NIC sits idle.
- The Storage Saturation: An autoscaler spins up 20 replicas. They all hammer the central object store. Metadata services hit rate limits, and egress saturates.
- The Fabric Collapse: At 100+ nodes, you're moving 14+ Terabytes. North-south links saturate. At $8/hr per GPU, 100 GPUs idling for 3 minutes costs roughly $40 per event.
The Deep Dive: How the P2P Swarm Actually Scales
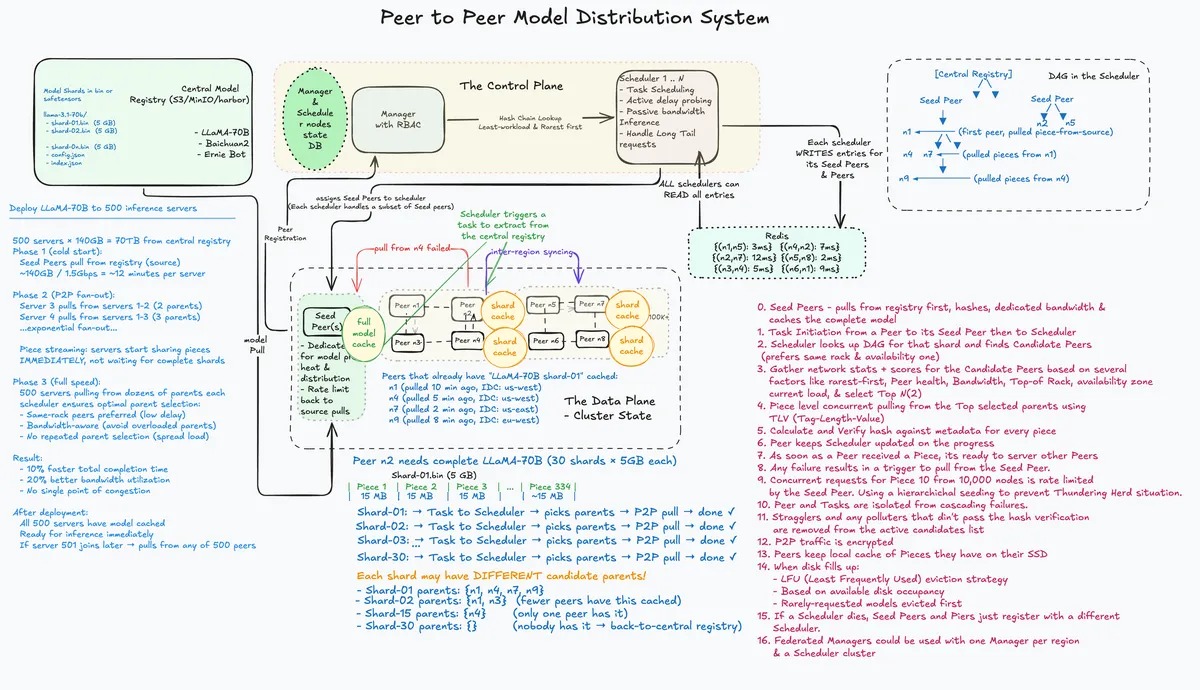
The P2P layer is more than a simple file share; it is a Learning Driven Task Scheduler that treats the cluster like a NUMA aware memory pool.
- Rarest First Piece Selection: Prevents Seed Peer bottlenecks by shredding the model across the fleet immediately.
- MultiFactor Scoring: The scheduler computes the optimal DAG based on Locality (Same Rack priority), Available Bandwidth, and Current Load.
- Learned Prediction: Using a Graph Attention Model, the system predicts link saturation before it happens, routing around hotspots during massive concurrent scale-up events.
- Integrity at TB Scale: Every 4MB piece is SHA-256 hashed. The Merkle Tree allows for out of order verification, ensuring bit-rot doesn't produce hallucinating tensors.
- Straggler Mitigation: Hedged Requests (speculative execution) trigger multiple peers to send the final 1% of the data, ensuring the P99 latency doesn't stall on a single slow node.
Architectural Evolution
The transition from a 102 second cold start to a 13 second page fault was not achieved by one tool, but by systematically removing serial dependencies in the loading pipeline.
Stage 1: Eliminating the CPU Wait (Streaming)
In the naive path, download and deserialization are serialized. The CPU sits idle during the download, and the GPU sits idle during deserialization.
- The Fix: Tensorizer (CoreWeave) and Run:ai. By using a flat binary format instead of a Python pickle, these tools overlap I/O and GPU memory allocation.
- The Result: Tensors materialize in VRAM as bytes arrive.
- Speedup: 1.7× (Time-to-first-token drops by ~40s).
Stage 2: Eliminating NIC Idle (Parallel Sharding)
A single TCP stream rarely saturates a 100 Gbps NIC due to window scaling limits.
- The Fix: Safetensors (Hugging Face). By sharding a 140GB model into 8–16 files, we can open parallel HTTP streams.
- The Result: NIC bandwidth is finally saturated, and in tensor parallel setups, each GPU rank pulls only its specific shard simultaneously.
- Speedup: 1.8×.
Stage 3: Eliminating the Thundering Herd (P2P Swarm)
Stages 1 and 2 solve the node problem, but they break the cluster problem. 100 nodes pulling parallel shards simultaneously will collapse any central storage origin.
- The Fix: Dragonfly (P2P) + Nydus (Lazy Loading). Dragonfly turns East-West bandwidth into a distributed cache. The origin seeds each shard once; the cluster distributes the rest. Nydus acts as the Page Fault handler, allowing the container to boot instantly while data hydrates in the background.
- Speedup: 7.7× (102s 13.3s).
The Final Frontier: The Memory-Centric Stack
The ultimate evolution is the Architectural Collapse of the loading path. We are moving from Loading Files to Mapping Memory.
Bypassing the CPU Bounce (GPUDirect Storage)
Historically, data makes a hop through the CPU's system memory (bounce buffer). -- The Shift: NVIDIA Magnum IO + GDS. This establishes a direct DMA path from the Network/NVMe PCIe GPU VRAM. -- The Result: The CPU is relegated to a traffic cop, and the model weights become pageable memory objects.
Disaggregated Storage Fabrics
- When you pair P2P with a Disaggregated Fabric (VAST/WEKA), storage itself becomes a horizontally scalable compute cluster. By using NVMe over Fabrics, we access remote flash via RDMA, which often outperforms local NVMe for large sequential reads.
The Architectural Gains Benchmark:
| Stage | Mechanism | Bottleneck Solved | Time (70B) | Speedup |
|---|---|---|---|---|
| Baseline | torch.load() |
— | 102.5s | 1.0x |
| Streaming | Tensorizer | CPU Deserialization | 59.7s | 1.7x |
| Direct-Path | Magnum IO + GDS | CPU Bounce Buffering | 38.2s | 2.7x |
| Swarmed | P2P + Dragonfly | North-South Saturation | 13.3s | 7.7x |
Closing Thoughts
We have moved from a file-centric world (Download → Write → Load) to a memory-centric world (Stream → Peer Verify → Direct-to-VRAM). The Terabyte Page Fault is now a system to be managed, where model weights are mapped from a rack scale memory fabric rather than being loaded from a disk.
References
- Dean & Barroso, The Tail at Scale (2013): https://www.barroso.org/publications/TheTailAtScale.pdf
- Dragonfly: AI-Driven P2P Distribution (CNCF, Ant Group, v2.1.0): https://d7y.io/
- NVIDIA GPUDirect Storage (GDS): https://docs.nvidia.com/gpudirect-storage/
- NVIDIA Magnum IO: https://developer.nvidia.com/magnum-io
- Nydus Image Service (CNCF): https://nydus.dev/
- Tensorizer (CoreWeave / EleutherAI): https://github.com/EleutherAI/tensorizer
- Run:ai Model Streamer: https://www.run.ai/
- Safetensors (Hugging Face): https://github.com/huggingface/safetensors
- Megatron-LM (NVIDIA): https://github.com/NVIDIA/Megatron-LM
- vLLM: https://github.com/vllm-project/vllm
- PyTorch Distributed Checkpointing: https://pytorch.org/docs/stable/distributed.checkpoint.html
- NVIDIA Triton Inference Server: https://github.com/triton-inference-server/server
- VAST Data: https://vastdata.com/
- WEKA: https://www.weka.io/
- CXL Consortium: https://www.computeexpresslink.org/
- NVMe-over-Fabrics: https://nvmexpress.org/nvme-over-fabrics/